Virtualization is method of logically dividing the system resources into virtualized resources and maps them to physical resources. This can be done either from Hardware (Intel VT) or Software (Hypervisor) an old idea developed by IBM in 60s and 70s.
Applications of Virtualization:
- Resource utilization
- Machines today are powerful, want to multiplex their hardware
- Can migrate VMs from one machine to another without shutdown
- Software use and development
- Can run multiple OSes simultaneously
- Can do system (e.g., OS) development at user-level
- Many other cool applications
- Debugging, emulation, security, speculation, fault tolerance…
- Common theme is manipulating applications/services at the granularity of a machine
- Specific version of OS, libraries, applications, Etc.
The Golden Standards:
In Popek and Goldberg’s 1974 paper they proposed three fundamentals characteristics for a software system to be called as a VMM.
- Fidelity: OS and applications should run without modifications.
- Performance: Majority of the Guest OS operations should executed directly on the hardware.
- Safety: The Guest OS shouldn’t take control over the system.
Types of virtualization:
- Partitioning: CPU is divided into different parts and each part works as an individual system (eg: LPARs)
- Full Virtualization: Creating a virtual instance that is not aware of the fact that it’s virtualized.
- Software Based: Binary Translation
- Hardware Based: KVM
- Paravirtualization: If the Guest OS is aware of it being virtualized (Needs some OS level Modifications) XEN
- Hybrid Virtualization: Paravirtualization + Full virtualization (ESXi, XEN)
- Container-Based virtualization: Container is an object that packages an application and all its dependencies (Docker)
Full Virtualization(Binary Translation) , Paravirtualization(XEN), Hybrid Virtualization(KVM) are the widely used virtualization techniques currently. VMM plays a critical role in allocating resources to the Guest OSes ensuring different Guest get allocated as per their requirements. Let’s see some of these techniques in detail below.
VMMs or Hypervisor can be classified into two types depending on their placement, If an hypervisor is directly runs on top of the hardware then it is calld as Type 1 hypervisor else if their’s an OS between hardware and hypervisor then it is called as Type 2 hypervisor
Adaptive Binary Translation (Software Virtualization)
Classical virtalization: Trap and Emulate based technique which was widely popular in 1974, Doesn’t follow the golden standards of Popek and Goldberg as virtualization techniques were run on x86 which is not classically virtualizable. it also faced different obstacles for being completely virtualized such as:
- Visibility of privilaged state.
- Lack of traps when privileged instructions run at user-level.
Vmware proposed a solution for this problem to overcome the semantic obstacles faced by classical virtualization by adding an intrepter layer between the Guest OS and physical CPU and customize this interpreter to prevent the leakage of privilaged state and correctly implement non-trapping instructions (popf).
Challenges for BinaryTranslation:
- De-Privileging guests.
- Protecting VMM from guest memory access
- Updating guest shadow data strutures.
Note: This approach is similar to running JVMs using JIT compilers.
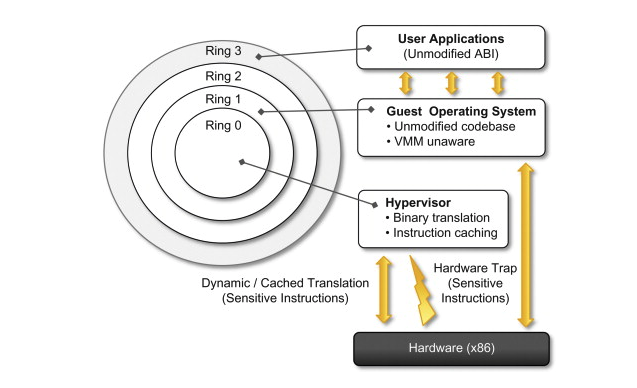
Vmware proposed a translator with these properties that takes care of this challenges:
- Binary: Takes binary x86 code as input.
- Dynamic: Translation happens at run-time.
- On Demand: Code is translated only when it is about to execute.
- System Level: It makes no assumptions on guest code. The VMM must run a buffer overflow that clobbers a return address.
- Subsetting: It returns a safe subset of instructions for Host to perform.
- Adaptive: Translated code adjusted in response to guest behavior.
How does translation work?
The binary translation is done dynamically, on-demand just before a chunk of code is executed, it is usually performed in small units called “basic blocks”. A basic block is a set of instructions that ends with a branch instruction but does not have any branch instructions inside. Such a block will always be executed start to finish by a CPU, and is therefore an ideal unit for translation. The translations of the basic blocks are cached. This means that the overhead of translating only happens the first time a block is executed.
To reduce the overhead of translating everything. The translated blocks are loaded at a different memory offset than the untranslated blocks, and are also usually larger than the original blocks. This means that both absolute and relative memory references need to be relinked in the translated code. Branch instructions at the end of a basic block can also be relinked to jump directly to another basic block. This is called “block chaining” and is an important performance optimization, But not all instructions can be translated such as
- PC-relative addressing
- Direct control flow
- Indirect control flow
- Privilaged instructions
While BT eliminates traps from privileged instructions it uses Adaptive Binary Translation to eliminate non-privileged instructions from accessing sensitive information such as page tables. by detecting instructions that trap frequently and adapt their translation.
Intel and AMD proposed new architectural changes that permit classical virtualization by introducing a new data structure called VMCB(virtual machine control block) which combines control state and subset state of guest virtual CPU. Which we will be discussing in detail when we analyze KVM which makes use of this new hardware changes.
Recent Advances and Important Features:
- Direct Execution: It’s runs guest user code in (CPL3) with some execptions for better efficiency and simplicity.
- Chaining Optimization to speed up inter-CCF(compiled code fragment) transfers.
- Heeds all of the golden standards. (Performance is not that good)
- Precise exceptions and trap elimination and callout avoidance some of the noteworthy features of VMware sofware virtualization solution.
- CPU-intensive apps: 2-10% overhead
- I/O-intensive apps: 25-60% overhead
Xen and the Art of Virtualization (Paravirtualization)
x86 Architecture made Virtualization very difficult as it was not designed with virtualization in mind. So it started to behave differently in kernal and user mode. so they have to come up with either full software emulation or binary translation. This made Xen a project at Cambridge computer laboratory to rethink about virtualization and come up with a new way which is now called as ParaVirtualization by,
- Designing a new interface for virtualization.
- Allowing guests to collbrate in virtualizations.
- Providing new interface to guests to reduce overhead of virtualization.
The hypervisor was first described in a SOSP 2003 paper called “Xen and the Art of Virtualization.” It was open sourced to allow a global community of developers to contribute and improve the hypervisor. The hypervisor remained an open source solution and has since become the basis of many commercial products.In 2013, the project went under The Linux Foundation. Accompanying the move, a new trademark “Xen Project” was adopted to differentiate the open source project from the many commercial efforts which used the older “Xen” trademark.
Xen still powers some of the largest cloud providers such as Amazon Web Services(AWS), Tencent, Alibaba Cloud, Etc. Although the current xen has been completed remolded by combinig the best features from Xen and HVM but it still follows the same core principles that they published in 2003 paper. by Univ of Cambridge computer laboratory. Xen proposes that to fully virtualize this kind of architectures we need to build a increased complexity and reduced performance virtual machines and argues that by allowing Guest OS access to the host OS we can better support time sensitive tasks and correctly handle TCP timeouts and RTT estimates which in return improves the performance of the virtual machines.
Xen showed that it was able to acheive all of this by introducing Hypervisior an abstarct machine on top on the host H/W which can avoid the difficulties of virtualizing all parts of the architecture. This is also called as ParaVirtualization .
Design Principles:
- Virtualization should allow isolation of processes and virtual machines.
- It should be able to support variety of Operating systems.
- Performance overhead between Host and Guest OS should be minimum.
Note: Although you need modify Guest OS a bit, you don’t need to modify Guest applications.
| Memory Management | |
|---|---|
| Segmentation | Cannot install fully-privileged segment descriptors and cannot overlap with the top end of the linear address space. |
| Paging | Guest OS has direct read access to hardware page tables, but updates are batched and validated by the hypervisor. A domain may be allocated discontiguous machine pages. |
| CPU | |
| Protection | Guest OS must run at a lower privilege level than Xen. |
| Exceptions | Guest OS must register a descriptor table for exception handlers with Xen. Aside from page faults, the handlers remain the same |
| System Calls | Guest OS may install a ‘fast’ handler for system calls, allowing direct calls from an application into its guest OS and avoiding indirecting through Xen on every call. |
| Interrupts | Hardware interrupts are replaced with a lightweight event system |
| Time | Each guest OS has a timer interface and is aware of both ‘real’ and ‘virtual’ time. |
| Device I/O | |
| Network, Disk, etc. | Virtual devices are elegant and simple to access. Data is transferred using asynchronous I/O rings. An event mechanism replaces hardware interrupts for notifications. |
The XEN VM Interface:

Memory Management:
As x86 doesn’t support Software managed TLB (Translation Lookaside Buffer), Xen allows Guest OS to create their own page tables by giving read only access to the hardware page tables.
- Thus to avoid TLB flush Xen exists in a 64MB section at the top of every address space, every time Guest OS requires to update the page tables or need write access to the page tables all this transactions are validated by Xen to ensure safety and isolation.
- This level segmentation is acheived by giving Guest OS a lower privilege than Xen and not modification accces to Xen address space.
CPU:
- Hypervisor creates an illusion that the virtual machine owns a set of CPUs and Memory with the host.
- Guest OS is modified to run in a lower privileage level than Host OS so any guest OS attempt to executes a privileaged instruction it is failed by the processor either silently or by taking a fault, since only XEN executes at a sufficient privileage level.
- Most of exceptions such as memory faults and software faults are similar to x86, the only type of instructions that effect the system performance are page faults and system calls
- System calls can be taken care effectively by aloowing each Guest OS to register a fast exception handler.
- Since same approach is not possible for page faults therefore there are always be delivered via Xen so that this register value can be saved for access in ring 1.
Double faultsresults in termination of Guest OS.
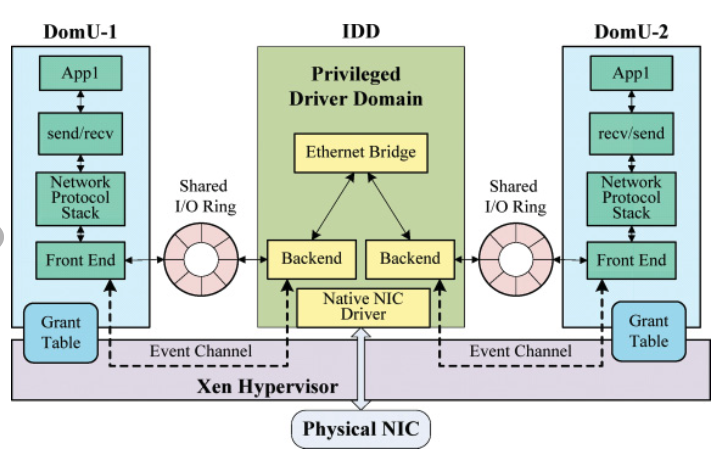
Device I/O:
- To this end, I/O data is transferred to and from each domain via Xen, using shared-memory, asynchronous bufferdescriptor rings
- When Xen boots up, it launches Dom0, the first privileged domain (Linux 2.6), but in theory can be any other OS that has been properly modified
- Dom0 is a privileged domain that can touch all hardware in the system
- Dom0 exports some subset of the the devices in the system to the other domains, based on each domain’s configuration
- The devices are exported as “class devices”, e.g. a block device or a network device.
Core Functionalities:
- Xen uses BVT algorithm for CPU scheduling (with option to control)
- Guest Os is aware of both real time, virual time and wall-clock time which can used for Guest OS for better task scheduling.
- Most of work only includes replacing privilaged instruction with hyper calls.
- Page tables of Guest OS are preregistered with MMU, and also handles the exceptions in bulk to reduce the overhead.
- Ballon Driver technique is used to allocate used memory or extra meory of different VMs via XEN.
- Disk access is done via VBD (vistual block devices) which are maintained by Domain 0.
- Round robin used to implement packet scheduler.
Recent Advances and Important Features:
- Requires minimal operating systems changes, and no userspace changes
- Provides secure isolation, resource control and QoS
- Close to native performance!
- Supports live migration of VMs
- Currently XEN was modified to use features from XEN and HVM for better performance.
kvm: the Linux Virtual Machine Monitor (Hardware Virtualization)
After a lot of virtualization papers starting their publications with x86 doesn’t support virtualization (NOT TRUE). Hardware manufactures such Intel and AMD started to virtualization extensions to x86 processors that can be used towrite relatively simple VMMs. Kvm is one of them which is a Kernel-based Virtual Machine for Linux system to run multiple os on top of them as a normal linux processes.
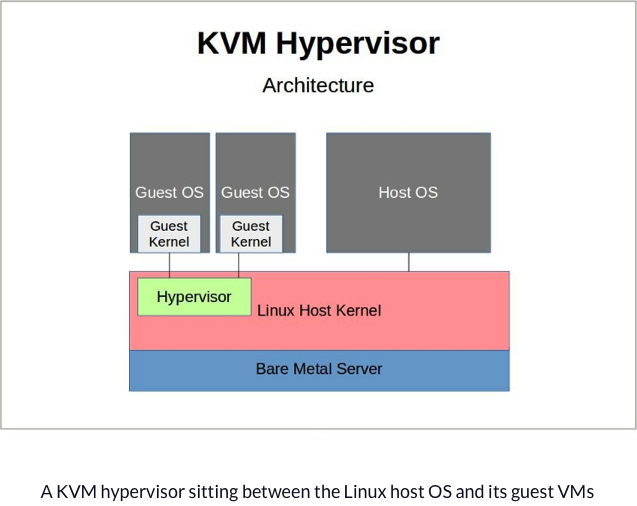
New Hardware Features:
- A new Guest Operating mode: A less privileaged level
- Hardware state switch: Hardware switches for guest and host mode
- Exit reason reporting: Error/Reason tracking while switching modes
How does KVM work?
- Start KVM:
/dev/kvmexposes a device node used by userspace to create and run VMs through set ofioctl()s.- Operation provided are:
- Creation of new VM
- Allocation of memory
- R/W to virtual cpu registers
- Injecting an interrupt into a virtual cpu.
- Running a virtual CPU.
- Memory Management:
- The qemu/kvm process runs mostly like a normal Linux program. It allocates its memory with normal malloc() or mmap() calls. If a guest is going to have 1GB of physical memory, qemu/kvm will effectively do a malloc(1«30), allocating 1GB of host virtual space. However, just like a normal program doing a malloc(), there is no actual physical memory allocated at the time of the malloc(). It will not be actually allocated until the first time it is touched. Once the guest is running, it sees that malloc()’d memory area as being its physical memory. If the guest’s kernel were to access what it sees as physical address 0x0, it will see the first page of that malloc() done by the qemu/kvm process.
- It used to be that every time a KVM guest changed its page tables, the host had to be involved. The host would validate that the entries the guest put in its page tables were valid and that they did not access any memory which was not allowed.
- CPU Management:
- At the outermost level, userspace calls the kernel to execute guest code until it encounters an I/O instruction, or until an external event such as arrival of a network packet or a timeout occurs. External events are represented by signals.
- At the kernel level, the kernel causes the hardware to enter guest mode. If the processor exits guest mode due to an event such as an external interrupt or a shadow page table fault, the kernel performs the necessary handling and resumes guest execution. If the exit reason is due to an I/O instruction or a signal queued to the process, then the kernel exits to userspace.
- At the hardware level, the processor executes guest code until it encounters an instruction that needs assistance, a fault, or an external interrupt.
I/O virtualization:
- KVM uses a kernel module to intercept I/O requests from a Guest OS, and passes them to QEMU, an emulator running on the user space of Host OS.
- kvm also provides a mechanism for userspace to inject interrupts into the guest.
- In order to efficiently support framebuffers, kvm allows mapping non-mmio memory at arbitrary addresses such as the pci region.
MMU virtualization:
- The actual set of page tables being used by the virtualization hardware are separate from the page tables that the guest thought were being used. The guest first makes a change in its page tables. Later, the host notices this change, verifies it, and then makes a real page table which is accessed by the hardware. The guest software is not allowed to directly manipulate the page tables accessed by the hardware. This concept is called shadow page tables.
- The VMX/AMD-V extensions allowed the host to trap whenever the guest tried to set the register pointing to the base page table (CR3).
- In order to improve guest performance, the virtual mmu implementation was enhanced to allow page tables to be cached across context switches. This greatly increases performance at the expense of much increased code complexity.
Recent Advances and Important Features:
- Both AMD and Intel sought solutions to these problems and came up with similar answers called EPT and NPT. They specify a set of structures recognized by the hardware which can quickly translate guest physical addresses to host physical addresses without going through the host page tables. This shortcut removes the costly two-dimensional page table walks.
- Improved utilization of resources and access to it by providing flexible storage
- A virtual machine created by it is a standard Linux process, scheduled by its native standard Linux scheduler.
- Leverages the capability of MMU (Memory management unit) in hardware to virtualize the memory with improvement in performance.
Comparsions Between Different Virtualizations:
| Paravirtualization (XEN) | Full Virtualization (ABT) | Hardware Virtualization (KVM) |
|---|---|---|
| Doesn’t provide complete isolation of Guest OS | Provides complete Isolation of Guest OS | Provides complete Isolation of Guest OS |
| Requires minimal OS modifications according to XEN. | Provides Execution of running unmodified Operating systems | Provides Execution of running unmodified Operating systems |
| More Secure | Less Secure compared to Paravirtualization | More secure |
| Requires hypercalls for execution. | Requires Binary Translation for operations | Doesn’t require any translations or hypercalls |
| Less Portable and compatiable | Easily portable and compatibility | Easily portable and compatibility |
| Faster as most of the operations are run directly on Hardware | Slower compared to Paravirtualization. | Directly propotional to number of exits occured during execution. |
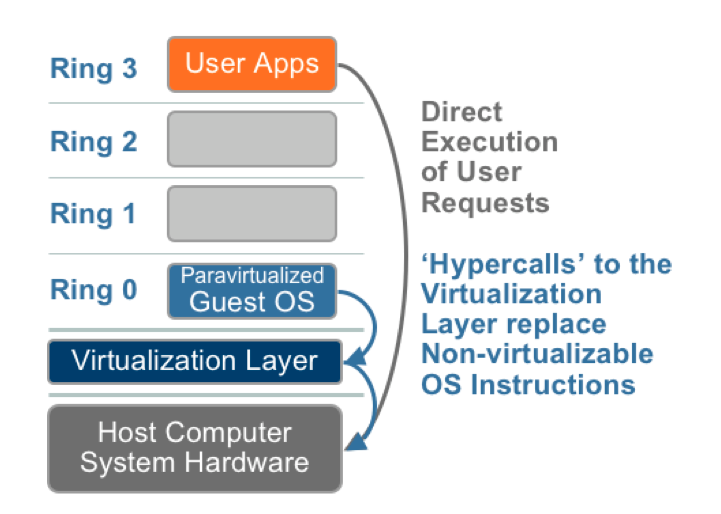
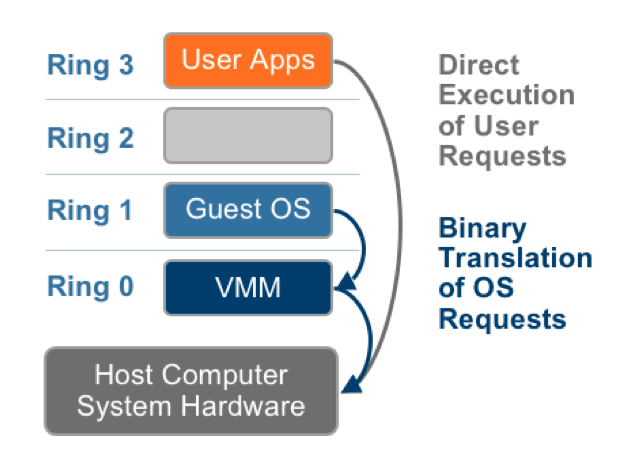
CPU Virtualization:
| Paravirtualization (XEN) | Full Virtualization (ABT) | Hardware Virtualization (KVM) |
|---|---|---|
 |
 |
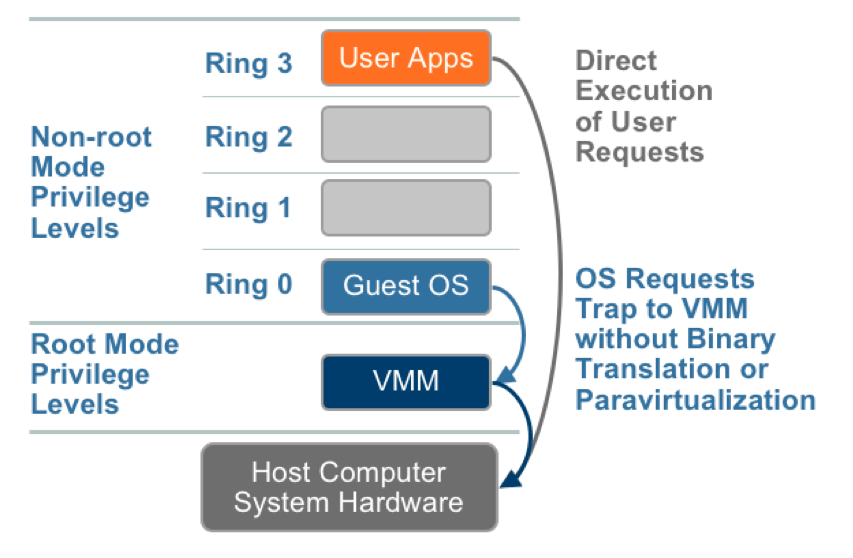 |
| The value proposition of paravirtualization is in lower virtualization overhead, but the performance advantage of paravirtualization over full virtualization can vary greatly depending on the workload. | The combination BT and Direct execution provides Full virtualization to run user level intructions at native speed and OS instructions by translating them on the fly and cache for further use. | As shown in the figure, privileged and sensitive calls are set to automatically trap to the hypervisor, removing the need for either binary translation or paravirtualization. |
Memory Virtualization:
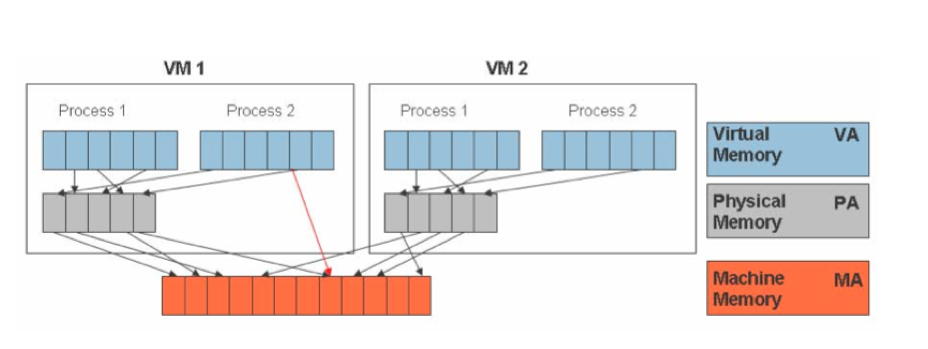
As shown in the figure, To run multiple virtual machines on a single system, another level of memory virtualization is required. In other words, one has to virtualize the MMU to support the guest OS. The guest OS continues to control the mapping of virtual addresses to the guest memory physical addresses, but the guest OS cannot have direct access to the actual machine memory.
Most of the virtualization techniques uses shadow page tables to accelerate the mappings of guest to host memory addresses.
I/O Virtualization:
I/O Virtualization technique involves sharing a single I/O resource among multiple virtual machines. Approaches include hardware based, software based, and hybrid solutions.
| XEN I/O | KVM I/O |
|---|---|
 |
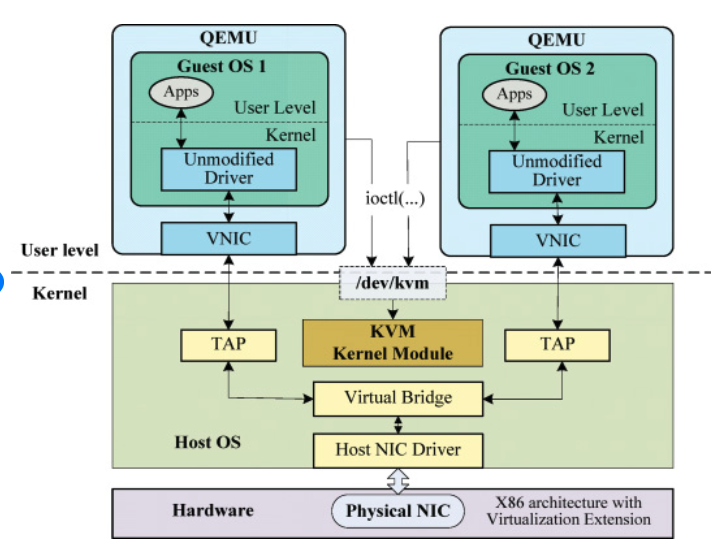 |
In Full virtualization The real devices are emulated for I/O virtualization.
In Para virtualization: The devices are exported as class devices, e.g. a block device or a network device, not as a specific Hardware model.
KVM vs XEN: Referred from A quantitative comparison between xen and kvm
During their tests kvm proved great stability and reliability: it never crashed and integrated seamlessly into our computing farm, without requiring any additional effort to the system administrators.
Their benchmarks showed that the CPU performance provided by the virtualization layer is comparable to the one provided by xen and in some cases it’s even better. Network performance is fair, showing some strange asymmetric behavior, but anyway we consider them acceptable.
Disk I/O seems to be the most problematic aspect, providing the VM poor performance, particularly when multiple machines concurrently access the disk. Anyway even xen based VM showed poor performance with this parameter, maybe caused by the solution adopted in our center, that is to provide virtual disks on a file.
To summarize, we can say that even if looking very promising, right now, xen hypervisor seems to be the best solution, particularly when using the para-virtualized approach.
Hardware Vs Software Virtualization:
Note: Most of the experiments put forth by the paper are done on 1st gen Hardware assisted processers which are not the same with recent developments
- Software and Hardware VMMs both perform well on compute-bound workloads.
- For workloads that perform I/O, create processes, or switch contexts rapidly, software outperforms hardware.
- In two workloads rich in system calls, the hardware VMM prevails.
Each virtualization technologies have their own advantages and disadvantages. The choice of virtualization heavily depends on use and cost.